Search Engine Bot Indexation / Crawl Control Tool (SEO) - Home Depot
My Role
Product Manager leading a scrum team devoted to SEO on HomeDepot.com.
Background
Search engines work via a 3 step process:
Crawl - a search engine bot follows links around the web to discover pages
Index - the search engine saves a version of the pages it crawls in its index
Rank - the search engine ranks the indexed pages in an attempt to best match a user’s search query
Much of SEO is focused on optimizing for the third step (rankings), but with a site as massive as HomeDepot.com, ensuring that search engine bots crawl and index the site in an optimal manner becomes a challenge in itself.
A key concern of ours was wasting crawl budget: search engines will only crawl and index a certain number of pages, and we wanted to ensure that the most important pages were those that were crawled and indexed. Otherwise, pages that weren’t as valuable to SEO — for example, pages that were duplicative, or were not part of the shopping experience — could waste valuable crawl/index budget.
Bots can be instructed to not index a page using a meta no-index tag. At Home Depot, determining which pages should or shouldn’t be indexed was largely a manual process of the SEO team maintaining lists in files and working with engineers to keep the site updated — a slow and error-prone process.
Project
In order to enable the SEO team to better manage how our pages were indexed, we built a tool that allows the team to create and manage no-index tags.

The tool consisted of a main page, where the SEO team could see a full list of no-index rules, what they targeted (site IDs), when they were created, by whom, and if there are any exceptions to these rules. Users can also delete or edit rules from this view. It was also possible to search for rules and to sort them by the column values (e.g. date modified), to export the full list, and to bulk upload rules en mass.
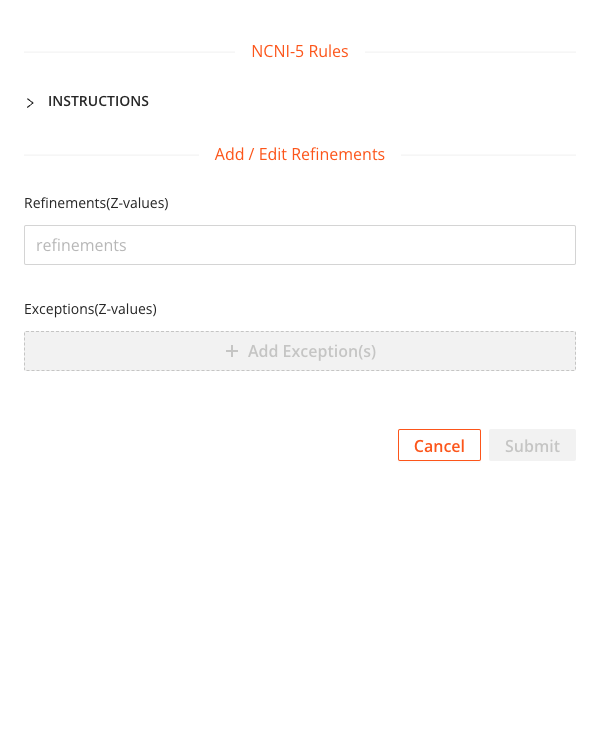
When creating a new rule, a user could input a Z-value (a product ID that is appended to a URL) to match. This was a broad match, so any Z-values that contained the string would be no-indexed (which allowed us to create rules for broad categories rather than use massive lists of Z-values). Exceptions to the matching logic could also be used (exact match) to exclude those product pages from receiving the no-index tag.